Import contents
Import contents to SyncCMS
Overview
SyncCMS supports importing data functionality, compatible with JSON, XML, and HTML formats.
Prerequisite Requirement
Before performing data imports, ensure you have working knowledge of XPath syntax.
How to Use XPath
To get you started quickly, we'll demonstrate how to use XPath to extract data with real-world examples in both XML and JSON. Our tool will automatically handle any necessary format conversions, so you only need to focus on entering the correct path.
XML Example
Let's assume the following XML data:
<?xml version="1.0" encoding="UTF-8"?>
<rss
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:atom="http://www.w3.org/2005/Atom" version="2.0"
xmlns:media="http://search.yahoo.com/mrss/">
<channel>
<item>
<title>
<![CDATA[Key takeaways from the PM's meeting with US president]]>
</title>
<description>
<![CDATA[A surprise letter from King Charles III to a possible trade deal - the key moments from Starmer's visit to the White House.]]>
</description>
<link>https://www.bbc.com/news/articles/cvgee7rl24ro</link>
<guid isPermaLink="false">https://www.bbc.com/news/articles/cvgee7rl24ro#0</guid>
<pubDate>Thu, 27 Feb 2025 22:22:26 GMT</pubDate>
<media:thumbnail width="240" height="135" url="https://ichef.bbci.co.uk/ace/standard/240/cpsprodpb/b415/live/ab1c8440-f5a0-11ef-9e61-71ee71f26eb1.jpg"/>
</item>
<item>
<title>
<![CDATA[Chris Mason: Starmer wins Trump over - but Ukraine uncertainty lingers]]>
</title>
<description>
<![CDATA[No 10 thinks the talks were a success but questions remain on defence, our political editor writes.]]>
</description>
<link>https://www.bbc.com/news/articles/c871120g92ro</link>
<guid isPermaLink="false">https://www.bbc.com/news/articles/c871120g92ro#0</guid>
<pubDate>Fri, 28 Feb 2025 06:52:33 GMT</pubDate>
<media:thumbnail width="240" height="135" url="https://ichef.bbci.co.uk/ace/standard/240/cpsprodpb/e707/live/24d79430-f5ad-11ef-9e61-71ee71f26eb1.jpg"/>
</item>
</channel>
</rss>
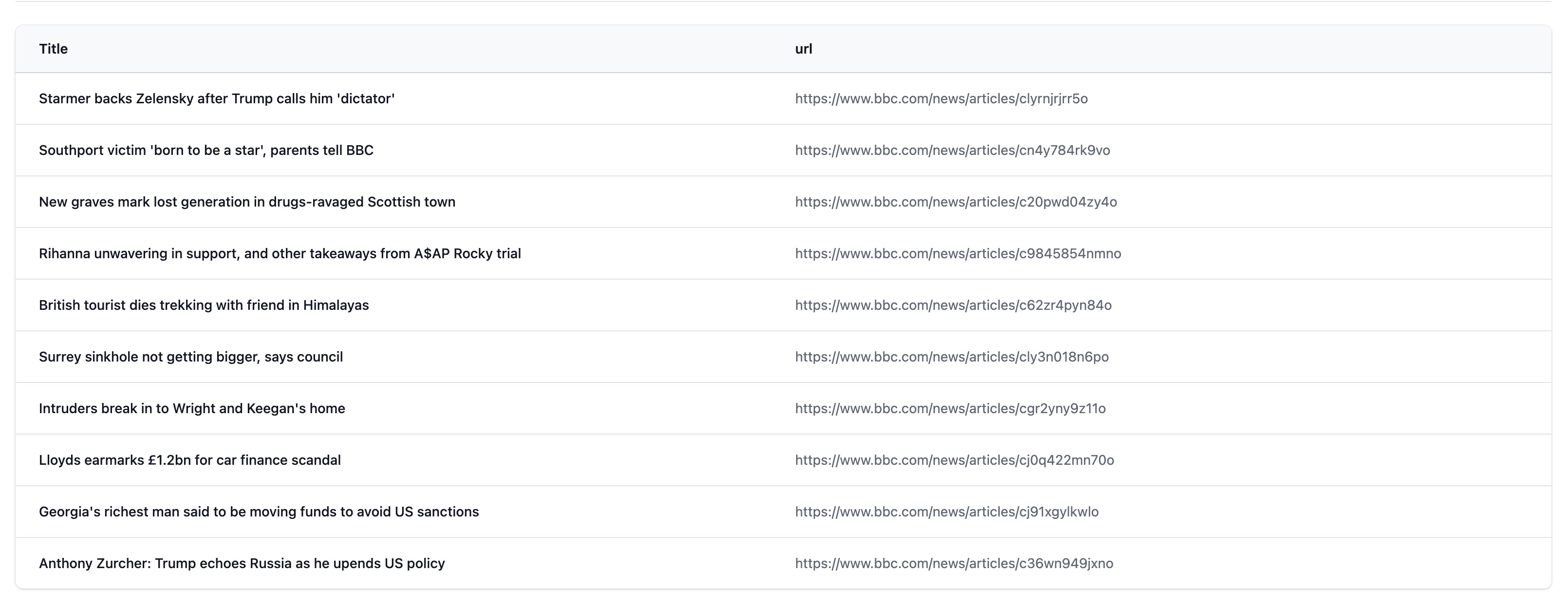
Example 1: Retrieve all the titles
XPath: //channel/item/title
Result:
Key takeaways from the PM's meeting with US president
Chris Mason: Starmer wins Trump over - but Ukraine uncertainty lingers
Explanation: Starting from the "channel" element, the XPath looks for all "item" elements and extracts the "title" of each one.
Example 2: Retrieve all the URL of thumbnail
XPath: //channel/item/media:thumbnail/@url
Result:
https://ichef.bbci.co.uk/ace/standard/240/cpsprodpb/b415/live/ab1c8440-f5a0-11ef-9e61-71ee71f26eb1.jpg
https://ichef.bbci.co.uk/ace/standard/240/cpsprodpb/e707/live/24d79430-f5ad-11ef-9e61-71ee71f26eb1.jpg
Explanation: Starting from the "channel" element, the XPath looks for all "item" elements and extracts the "url" of the "thumbnail" of each one.
JSON Example
Now let's look at JSON data. Assume we have the following JSON:
{
"channel": {
"item": [
{
"title": "Key takeaways from the PM's meeting with US president",
"description": "A surprise letter from King Charles III to a possible trade deal - the key moments from Starmer's visit to the White House.",
"link": "https://www.bbc.com/news/articles/cvgee7rl24ro",
"guid": "https://www.bbc.com/news/articles/cvgee7rl24ro#0",
"pubDate": "Thu, 27 Feb 2025 22:22:26 GMT",
"thumbnail": {
"_width": "240",
"_height": "135",
"_url": "https://ichef.bbci.co.uk/ace/standard/240/cpsprodpb/b415/live/ab1c8440-f5a0-11ef-9e61-71ee71f26eb1.jpg"
}
},
{
"title": "Chris Mason: Starmer wins Trump over - but Ukraine uncertainty lingers",
"description": "No 10 thinks the talks were a success but questions remain on defence, our political editor writes.",
"link": "https://www.bbc.com/news/articles/c871120g92ro",
"guid": "https://www.bbc.com/news/articles/c871120g92ro#0",
"pubDate": "Fri, 28 Feb 2025 06:52:33 GMT",
"thumbnail": {
"_width": "240",
"_height": "135",
"_url": "https://ichef.bbci.co.uk/ace/standard/240/cpsprodpb/e707/live/24d79430-f5ad-11ef-9e61-71ee71f26eb1.jpg",
"__prefix": "media"
}
}
]
}
}
Example: Retrieve all the titles
XPath: //channel/item/*/title
Result:
Key takeaways from the PM's meeting with US president
Chris Mason: Starmer wins Trump over - but Ukraine uncertainty lingers
Explanation: Starting from the "channel" element, the XPath looks for all "item" elements and extracts the "title" of each one.
Import Directly via Provided URL
When importing using this method, the fields in the URL you provide must align with the fields of the content type you've configured.
XML Format Data
As illustrated below, you need to map the XML data provided to the fields of the content type you've configured.
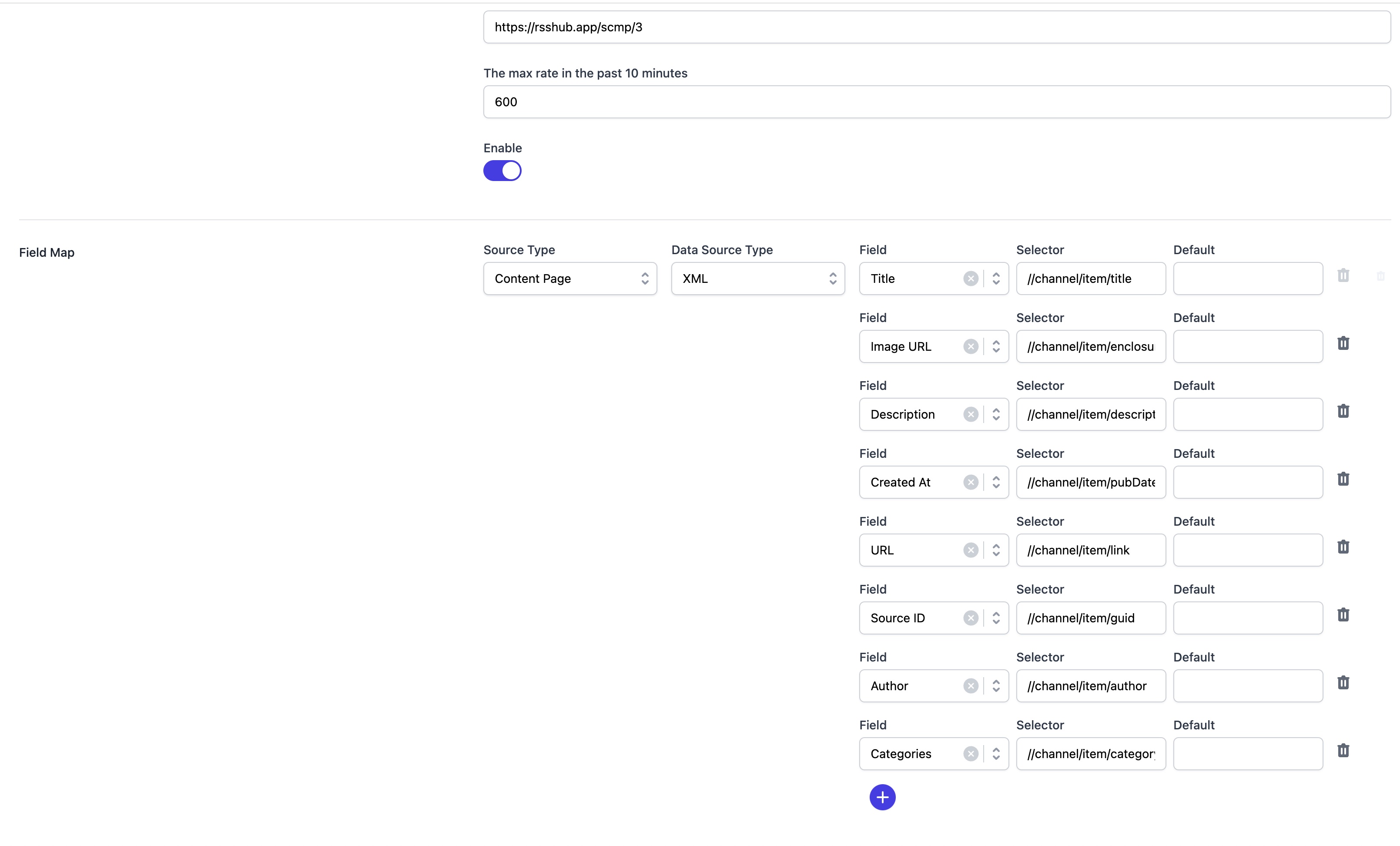
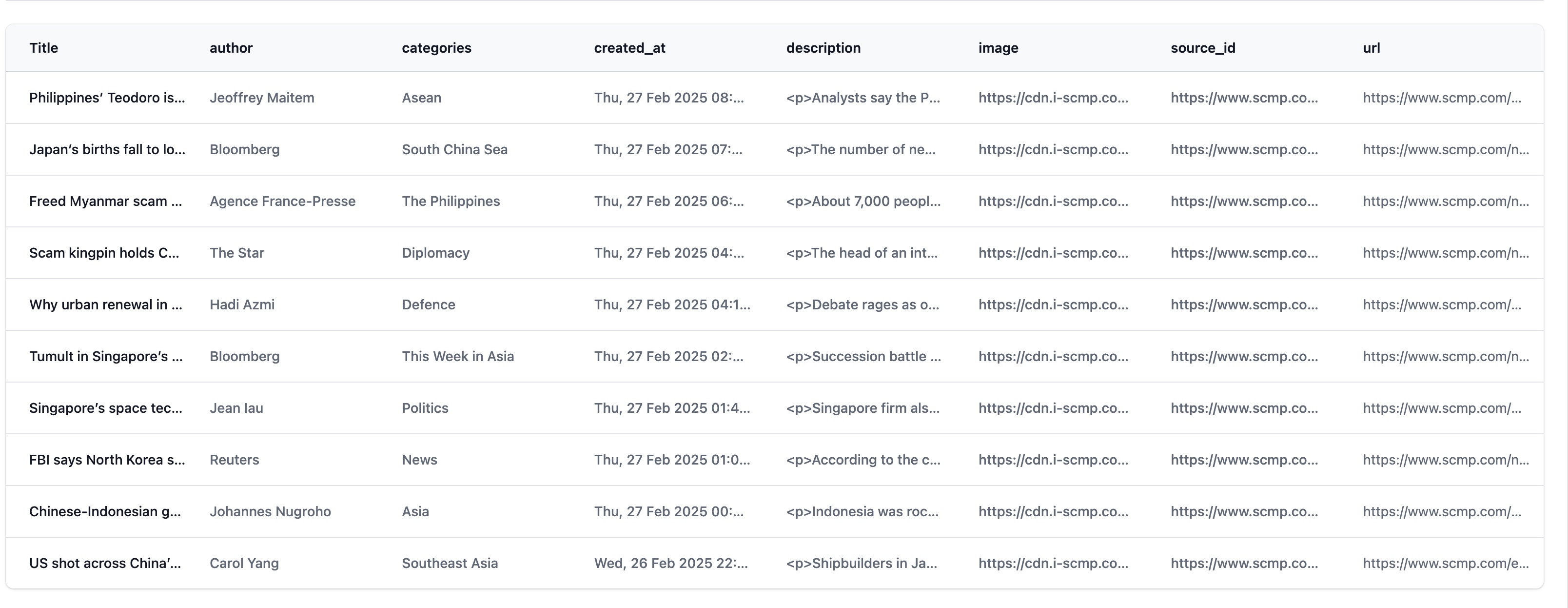
Preview
JSON Format Data
As shown below, you will map the provided JSON data to the fields of the content type you've configured.
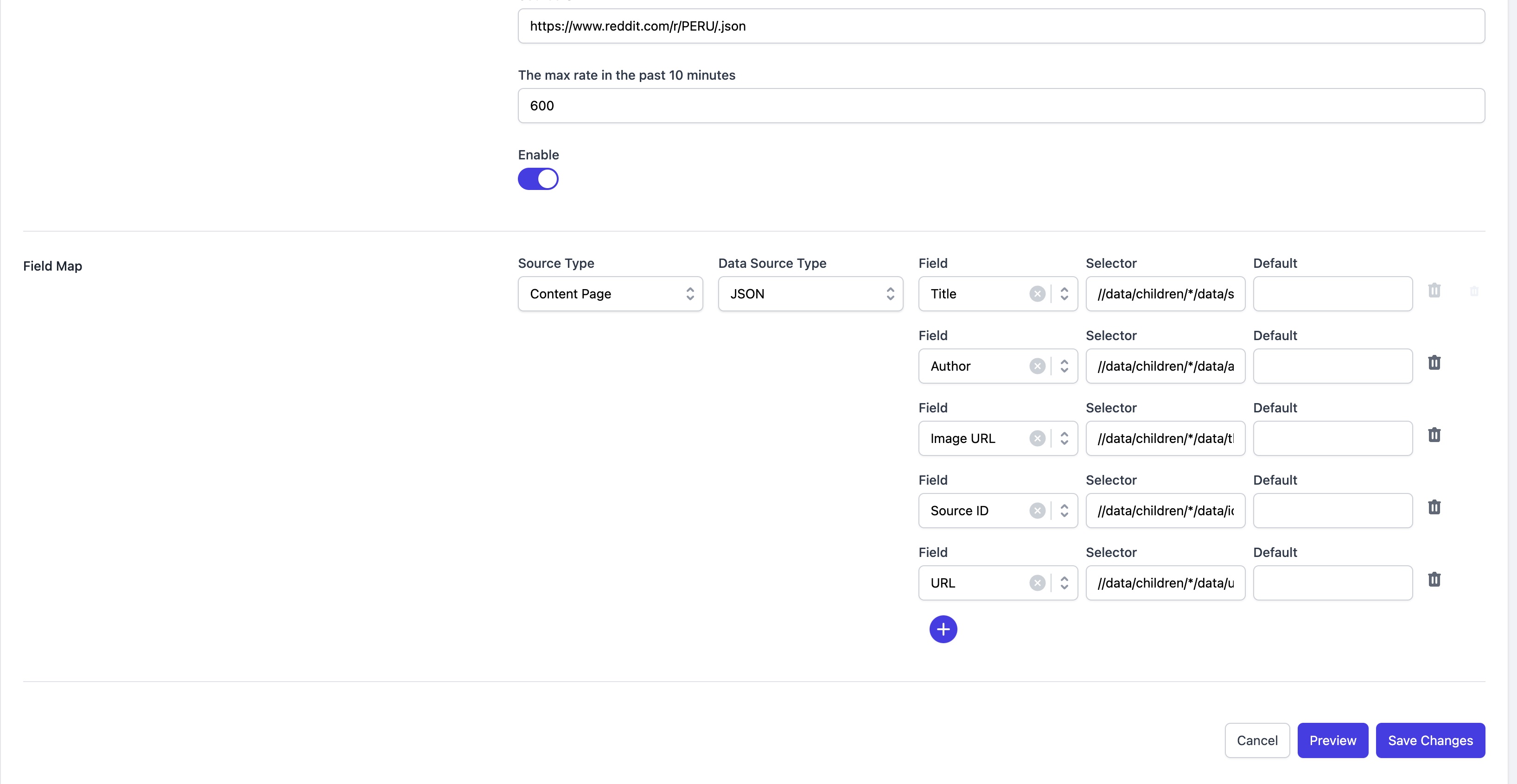
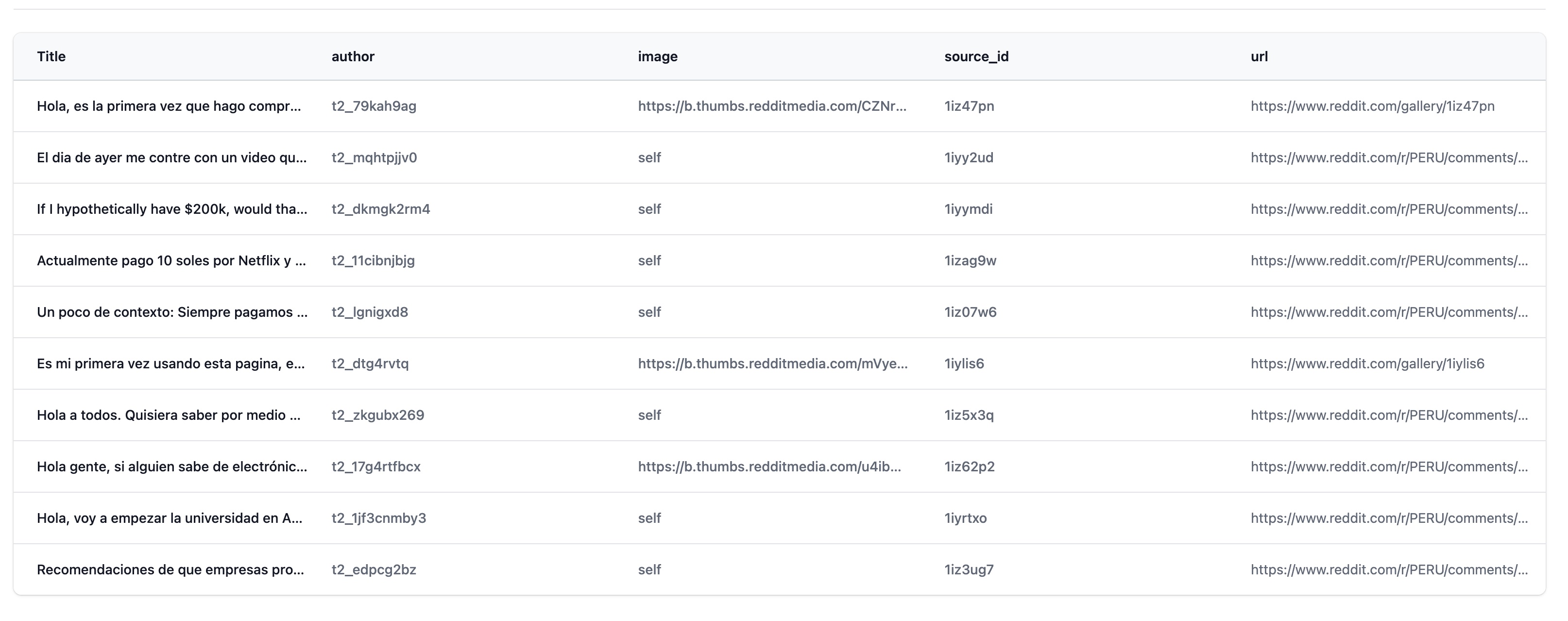
Preview
Fetch a set of URLs from the provided URL, then extract the content from each URL in the set.
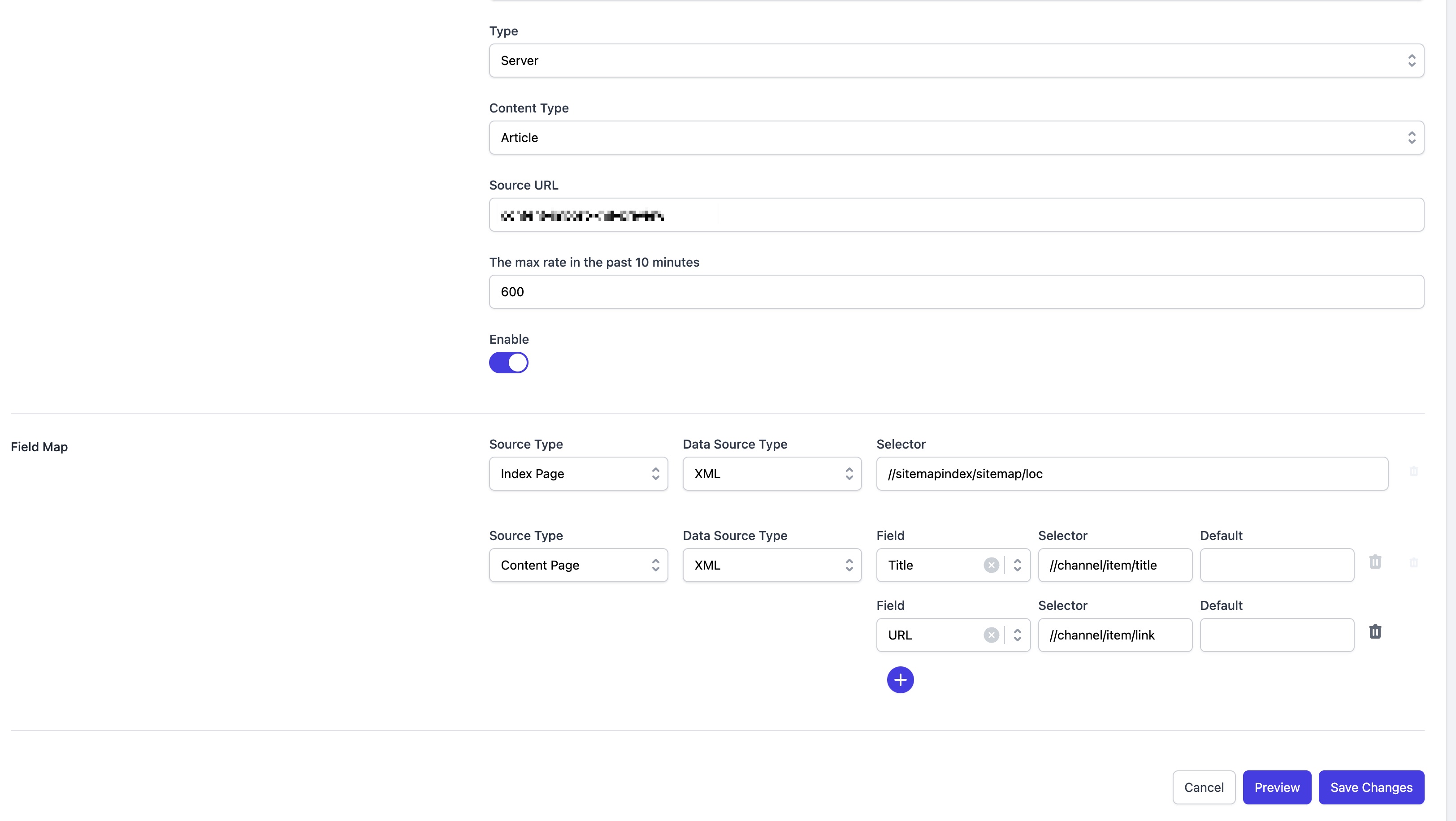
Retrieve All URLs for Importing
You will need to configure the entry URL for importing in the settings page, and then define how to obtain article links in the Field Map section. For a standard RSS feed, you can enter //channel/item/link in the Index Page field of Field Map to extract the article links.
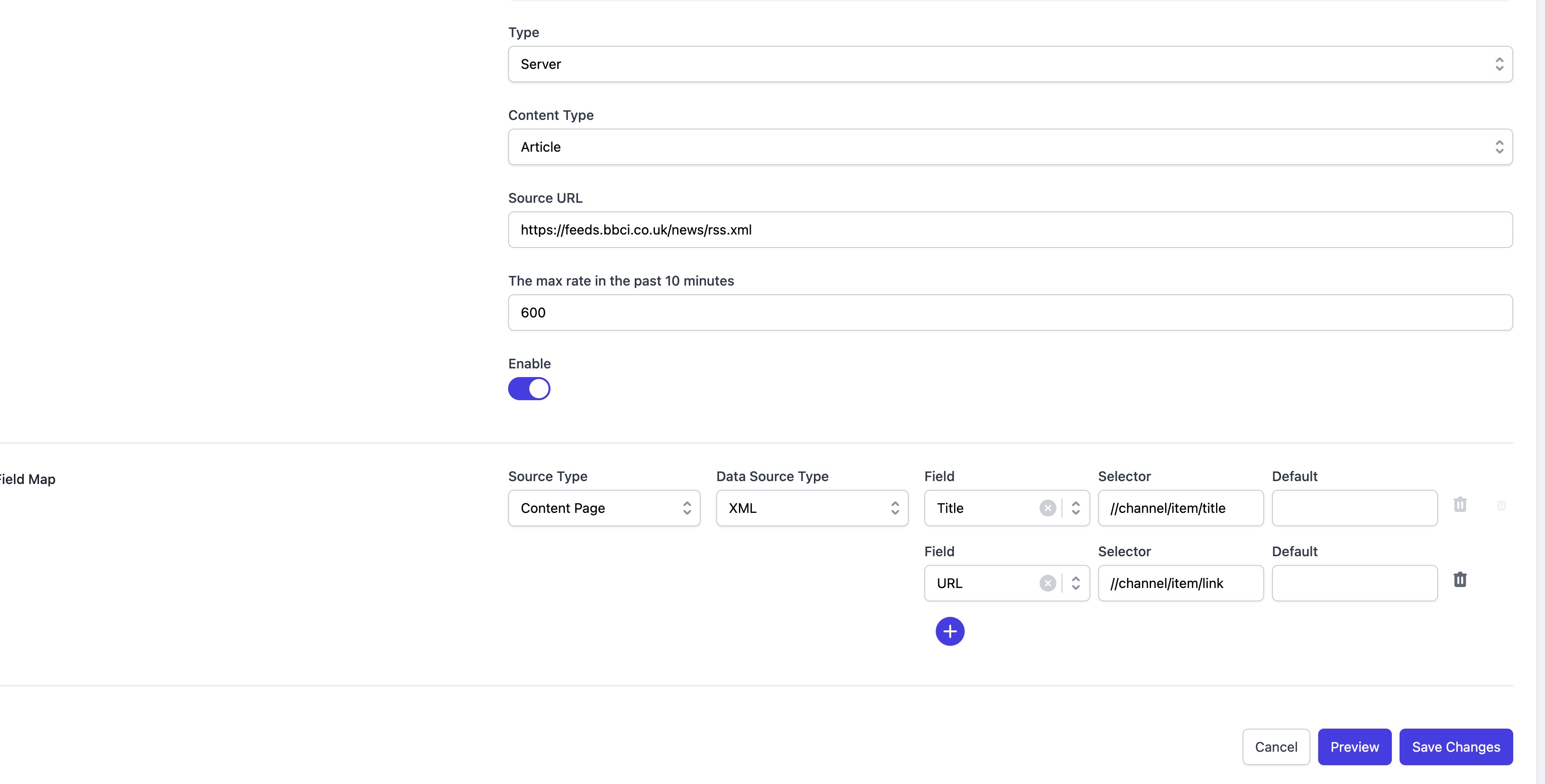
Extract Article Page Content
In the Field Map section, you will need to specify how to capture the content from the article page.
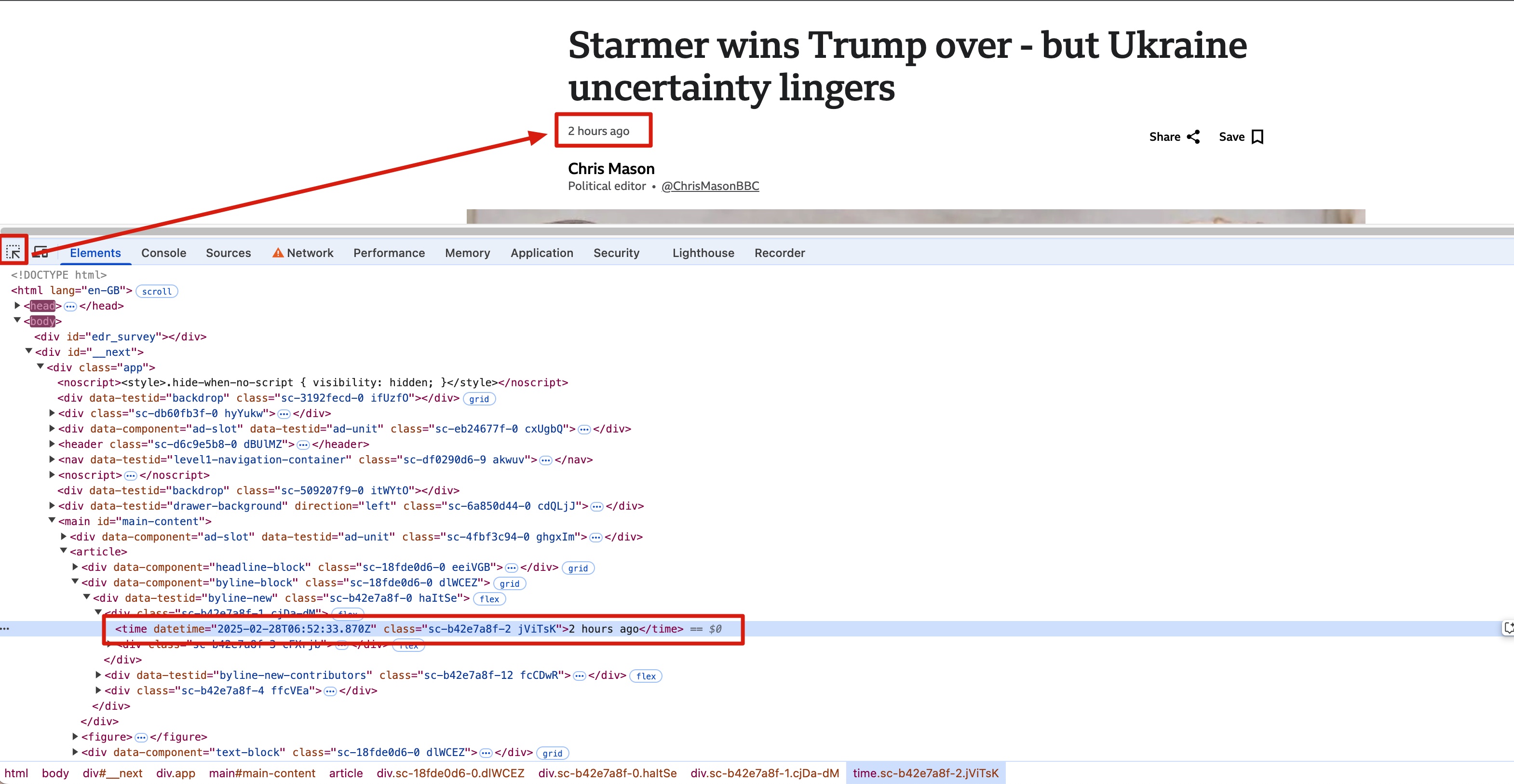
How to Get the XPath Path of an Element in Inspect
Once the article page is open, right-click and select the Inspect option.
In the Inspect window that appears, click the Elements tab and locate the element corresponding to the Content Page. Alternatively, you can use the Selector feature in the Inspect tool to capture the XPath of an element.
Next, click Copy -> Copy XPath to obtain the element's XPath.
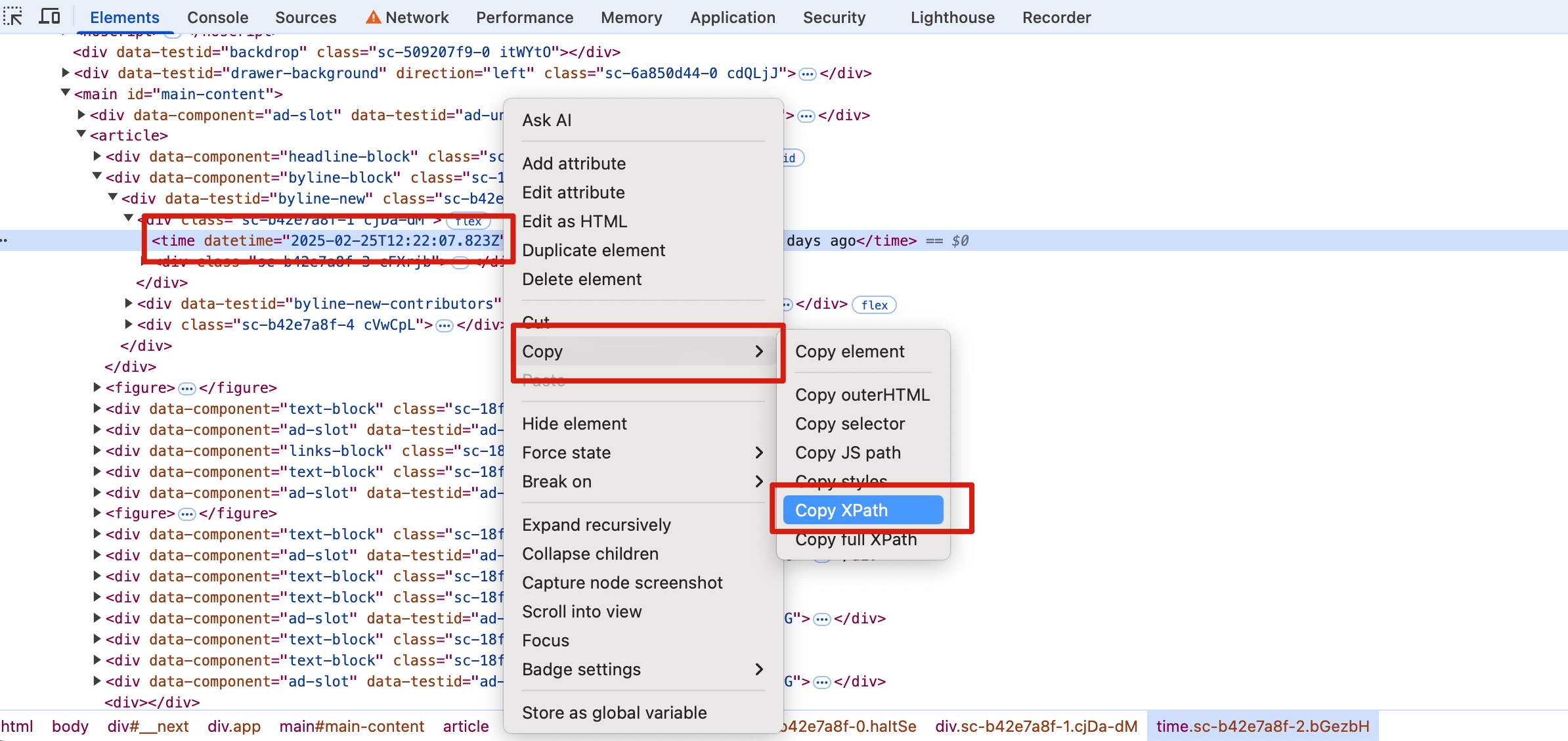
If you wish to extract a specific attribute of an element, you can add /@attribute_name to the XPath. For example, to retrieve the datetime attribute shown in the image above, append /@datetime to the XPath.
Preview and Import
Once you've completed the above configurations, you can click the "Preview" button to check the results. The image below provides an example of the preview screen.
After confirming that everything is correct in the preview, click "Save" to import the data.